モデル概観グラフ
Discriminator
loss
loss
Generator
loss
loss
Real
Fake
Prediction of
Samples
Samples
Discriminator
Generator
Gradients
Gradients
Real
Fake
Samples
Noise
1
生成器がノイズからサンプルを生成
2
識別器がサンプルを分類
3
識別器損失を計算
4
識別器勾配を計算
5
勾配に基づいて識別器を更新
1
生成器がノイズからサンプルを生成
2
識別器が偽のサンプルのみを分類
3
生成器損失を計算
4
生成器勾配を計算
5
勾配に基づいて生成器を更新
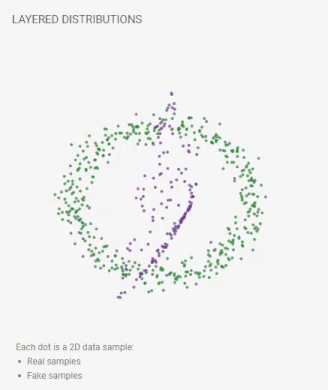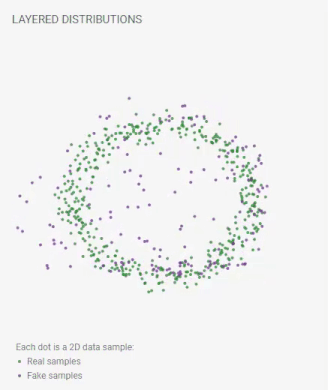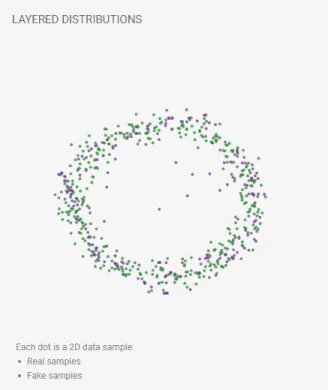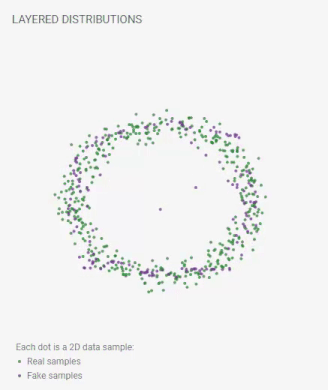
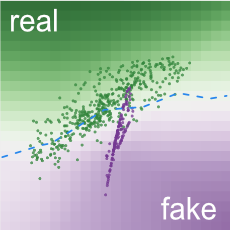
重層分布
各点は2Dデータサンプルです:
実際のサンプル;
偽のサンプル。
格子セルの背景色は
識別器の分類を表しています。
緑の領域 のサンプルは実際のものである可能性が高く、 紫の領域 のものは偽である可能性が高いです。
緑の領域 のサンプルは実際のものである可能性が高く、 紫の領域 のものは偽である可能性が高いです。
多様体は
生成器のノイズ空間からの変換結果を表しています。
不透明度は密度を符号化します: 濃い紫は小さな領域により多くのサンプルがあることを意味します。
不透明度は密度を符号化します: 濃い紫は小さな領域により多くのサンプルがあることを意味します。
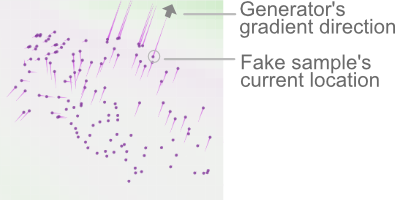
偽のサンプルからのピンクの線は
勾配を生成器に対して表しています。
このサンプルは生成器の損失を減少させるために 右上に移動する必要があります。
このサンプルは生成器の損失を減少させるために 右上に移動する必要があります。
上に分布を描き、適用ボタンをクリックしてください。
Metrics